In this, the last of my three posts on uncertainty, I complete the cycle I started with a look at the responses (healthy and unhealthy) to uncertainty and followed up with an examination of the Margin of Safety, by taking a more extended look at one approach that I have found helpful in dealing with uncertainty, which is to run simulations. Before you read this post, I should warn you that I am not an expert on simulations and that the knowledge I bring to this process is minimalist and my interests are pragmatic. So, if you are an expert in statistics or a master simulator, you may find my ramblings to be amateurish and I apologize in advance.
- Discrete versus Continuous Distributions: Assume that you are valuing an oil company in Venezuela and that you are concerned that the firm may be nationalized, a risk that either occurs or does not, i.e., a discrete risk. In contrast, the oil company's earnings will move with oil prices but take on a continuum of values, making it a continuous risk. With currency risk, the risk of devaluation in a fixed exchange rate currency is discrete risk but the risk in a floating rate currency is continuous.
- Symmetric versus Asymmetric Distributions (Symmetric, Positive skewed, Negative skewed): While we don't tend to think of upside risk, risk can deliver outcomes that are better than expected or worse than expected. If the magnitude and likelihood of positive outcomes and negative outcomes is similar, you have a symmetric distribution. Thus, if the expected operating margin for Apple is 25% and can vary with equal probability from 20% to 30%, it is symmetrically distributed. In contrast, if the expected revenue growth for Apple is 2%, the worse possible outcome is that it could drop to -5%, but there remains a chance (albeit a small one) that revenue growth could jump back to 25% (if Apple introduces a disruptive new product in a big market), you have an a positively skewed distribution. In contrast, if the expected tax rate for a company is 35%, with the maximum value equal to the statutory tax rate of 40% (in the US) but with values as low as 0%, 5% or 10% possible (though not likely), you are looking at a negatively skewed distribution.
- Extreme outcome likelihood (Thin versus Fat Tails): There is one final contrast that can be drawn between different risks. With some variables, the values will be clustered around the expected value and extreme outcomes, while possible, don't occur very often; these are thin tail distributions. In contrast, there are other variables, where the expected value is just the center of the distribution and actual outcome that are different from the expected value occur frequently, resulting in fat tail distributions.
While the glass jar simulation is still feasible for simulating simple processes with one or two variables that take on only a few outcomes, it is not a comprehensive way of simulating more complex processes or continues distributions. In fact, the biggest impediment to using simulation until recently would have been the cost of running one, requiring the use of a mainframe computer. Those days are now behind us, with the evolution of technology both in the form of hardware (more powerful personal computers) and software. Much as it is subject to abuse, Microsoft Excel has become the lingua franca of valuation, allowing us to work with numbers with ease. There are some who are conversant enough with Excel's bells and whistles to build simulation capabilities into their spreadsheets, but I am afraid that I am not one of those. Coming to my aid, though, are offerings that are add-ons to Excel that allow for the conversion of any Excel spreadsheet almost magically into a simulation.
I normally don't make plugs for products and services, even if I like them, on my posts, because I am sure that you get inundated with commercial offerings that show up insidiously in Facebook and blog posts. I am going to make an exception and praise Crystal Ball, the Excel add-on that I use for simulations. It is an Oracle product and you can get a trial version by going here. (Just to be clear, I pay for my version of Crystal Ball and have no official connections to Oracle.) I like it simply because it is unobtrusive, adding a menu item to my Excel toolbar, and has an extremely easy learning curve.
My only critique of it, as a Mac user, is that it is offered only as a PC version and I have to run my Mac in MS Windows, a process that I find painful. I have also heard good things about @Risk, another excel add-on, but have not used it.
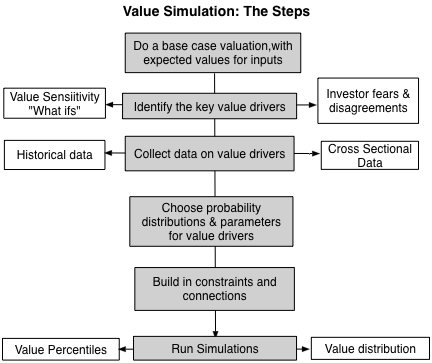
The first place to start a simulation is with a base case valuation. In a base case valuation, you do a valuation with your best estimates for the inputs into value from revenue growth to margins to risk measures. Much as you will be tempted to use conservative estimates, you should avoid the temptation and make your judgments on expected values. In the case of Apple, the numbers that I use in my base case valuation are very close to those that I used just a couple of months ago, when I valued the company after its previous earnings report and are captured in the picture below:
 |
| Download spreadsheet |
In my base case, at least, it looks like Apple is significantly under valued, priced at $93/share, with my value coming in at $126.47, just a little bit lower my valuation a few months ago. I did lower my revenue growth rate to 1.50%, reflecting the bad news about revenues in the most recent 10q.
collecting data on these variables, as a precursor for developing probability distributions. In developing the
distributions, you can draw on the following:
- Past data: If the value driver is a macroeconomic variable, say interest rates or oil prices, you can draw on historical data going back in time. My favored site for all things macroeconomic is FRED, the Federal Reserve data site in St. Louis, a site that combines great data with an easy interface and is free. I have included data on interest rate, inflation, GDP growth and the weighted dollar for those of you interested in US data in the attached link. For data on other countries, currencies and markets, you can try the World Bank data base, not as friendly as FRED, but rich in its own way.
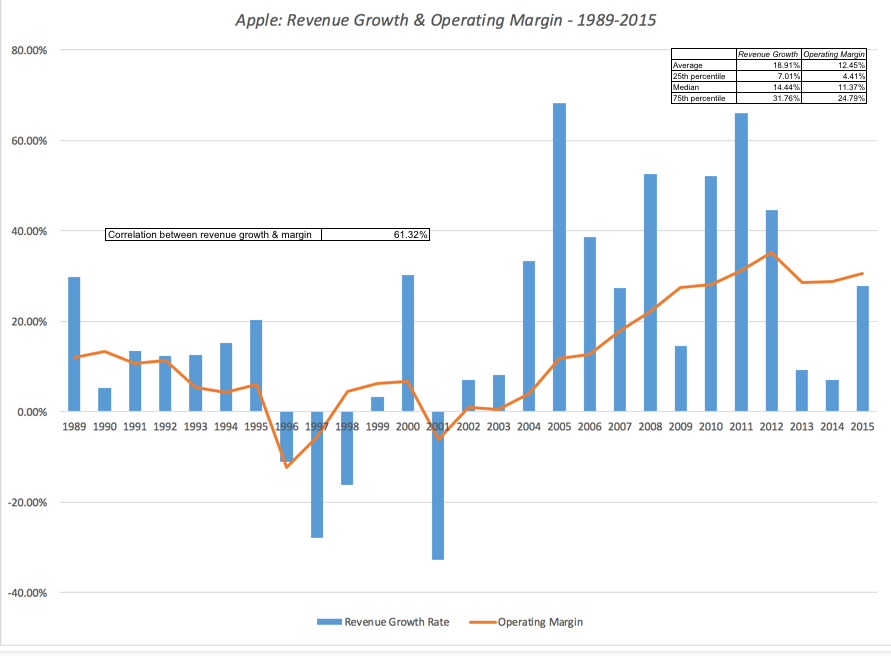
- Company history: For companies that have been in existence for a long time, you can mine the historical data to get a measure of how key company-specific variables (revenues, operating margin, tax rate) vary over time.
- Sector data: You can also look at cross sectional differences in key variables across companies in a sector. Thus, to estimate the operating margin for Amazon, you could look at the distribution of margins across retail companies.: If the value driver is a macroeconomic variable, say interest rates or oil prices, you can draw on historical data going back in time. My favored site for all things macroeconomic is FRED, the Federal Reserve data site in St. Louis, a site that combines great data with an easy interface and is free. I have included data on interest rate, inflation, GDP growth and the weighted dollar for those of you interested in US data in the attached link. For data on other countries, currencies and markets, you can try the World Bank data base, not as friendly as FRED, but rich in its own way.


There is no magic formula for converting the data that you have collected into probability distributions, and as with much else in valuation, you have to make your best judgments on three dimensions.
- Distribution Type: In the section above, I broadly categorized the uncertainties you face into discrete vs continuous, symmetric vs skewed and fat tail vs thin tail. At the risk of being tarred and feathered for bending statistical rules, I have summarized the distribution choices based on upon these categorizations. The picture is not comprehensive but it can provide a road map though the choices:

- Distribution Parameters: Once you have picked a distribution, you will have to input the parameters of the distribution. Thus, if you had the good luck to have a variable be normally distributed, you will only be asked for an expected value and a standard deviation. As you go to more complicated distributions, one way to assess your parameter choices to look at the full distribution, based upon your parameter choices, and pass it through the common sense test.

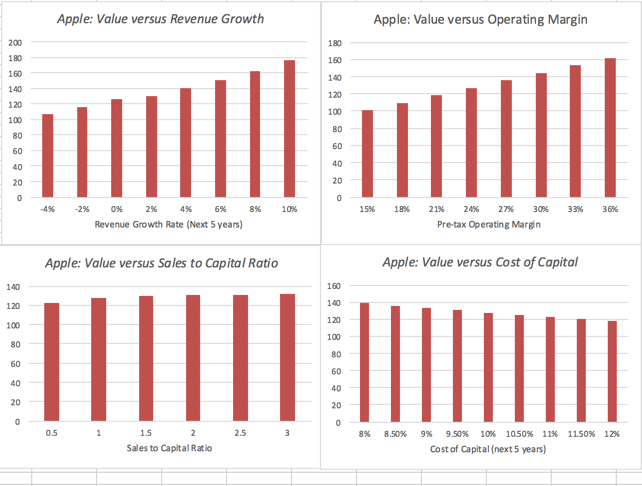
In the case of Apple, I will use the historical data from the company, the cross sectional distribution of revenue growth across older technology companies as well as a healthy dose of subjective reasoning to pick a lognormal distribution, with parameters picked to yield values ranging from -4% on the downside to +10% on the upside. On the target operating margin, I will build my distribution around the 25% that I assumed in my base case and assume more symmetry in the outcomes; I will use a triangular distribution to prevent even the outside chance of infinite margins in either direction.
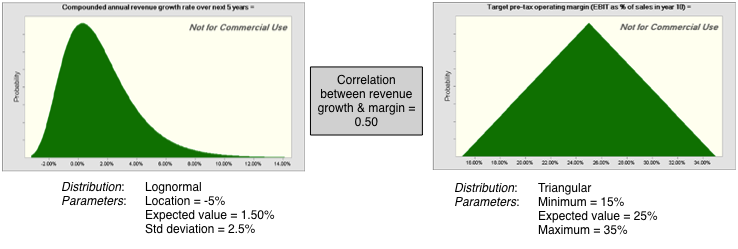
Note the correlation between the two, which I will talk about in the next section.
There are two additional benefits that come with simulations. The first is that you can build in constraints that will affect the company's operations, and its value, that are either internally or externally imposed. For an example of an external constraint, consider a company with a large debt load. That does not apply to Apple but it would to Valeant. If the company's value drops below the debt due, you could set the equity value to zero, on the assumption that the company will be in default. As another example, assume that you are valuing a bank and that you model regulatory capital requirements as part of your valuation. If the regulatory capital drops below the minimum required, you can require the company to issue more shares (thus reducing the value of your equity). The second advantage of a simulation is that you can build in correlations across variables, making it more real life. Thus, if you believe that bad outcomes on margins (lower margins than expected) are more likely to go with bad outcomes on revenue growth (revenue growth lower than anticipated), you can build in a positive correlation between the variables. With Apple, I see few binding constraints that will affect the valuation. The company has little chance of default and is not covered by regulatory constraints on capital. I do see revenues and operating margins moving together and I build in this expectation by assuming a correlation of 0.50 (lower than the historical correlation of 0.61 between revenues and operating margin from 1989 to 2015 at Apple).
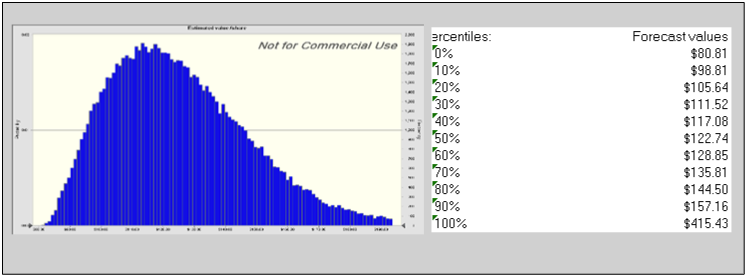
The percentiles of value and other key statistics are listed on the side. Could Apple be worth less than $93/share. Yes, but the probability is less than 10%, at least based on my assumptions. Having bought and sold Apple three times in the last six years (selling my shares last summer), this is undoubtedly getting old, but I am an Apple shareholder again. I am not a diehard believer in the margin of safety, but if I were, I could use this value distribution to create a more flexible version of it, increasing it for companies with volatile value distributions and reducing it for firms with more stable ones.
The most serious concern that I have, as an investor, is that I am valuing cash , which at $232 billion is almost a third of my estimated value for Apple, as a neutral asset (with an expected tax liability of $28 billion). Some of you, who have visions of Apple disrupting new businesses with the iCar or the iPlane may feel that this is too pessimistic and that there should be a premium attached for these future disruptions. My concern is the opposite, i.e., that Apple will try to do too much with its cash, not too little. In my post on aging technology companies, I argued that, like aging movie stars in search of youth, some older tech companies throw money at bad growth possibilities. With the amount of money that Apple has to throw around, that could be deadly to its stockholders and I have to hope and pray that the company remains restrained, as it has been for much of the last decade.
Conclusion
YouTube video
Attachments
- Paper on probability distributions
- Apple valuation - May 2016
- Link to Oracle Crystal Ball trial offer



Aut amet voluptatum alias temporibus. Maxime quia repudiandae ut quidem illo quas. Doloribus possimus voluptate et saepe odit maxime itaque. Perspiciatis consequatur beatae perspiciatis sit molestias commodi reiciendis. Quisquam et excepturi autem et officia blanditiis. Optio autem ut quod temporibus. Deserunt laudantium voluptatum aspernatur cupiditate reprehenderit minus laboriosam.
Suscipit excepturi sunt natus repudiandae quae debitis voluptatum maiores. Perferendis cumque eum neque soluta debitis. Nihil id asperiores rerum voluptatem nam ut. Quas ipsum dolorem reiciendis voluptas consequuntur. Ut et ullam asperiores quasi id est in ullam. Consequatur facilis cumque et id numquam quod dolores. Neque voluptatem quas ipsum rem adipisci corporis error.
Iste et harum similique. Et ab voluptatem voluptas.
See All Comments - 100% Free
WSO depends on everyone being able to pitch in when they know something. Unlock with your email and get bonus: 6 financial modeling lessons free ($199 value)
or Unlock with your social account...