Machine Learning project on Excel and M&A due diligence
Hey everyone,
I’m a software engineer from Amsterdam, and I've been fiddling with a side project that led me down an interesting road. I wanted to reach out for advice or help. Please feel free to jump to the TL;DR (Too Lazy Didn't Read) at the bottom of this post to get straight to the point.
A bit of context on why I’m building this: I’ve been teaching myself the math behind machine learning. I haven't had the chance to go to university, so this project is essentially my Rosetta Stone for applying what I've learned. I wanted to apply my skills to a sector that’s always fascinated me (financial services), so I started talking to M&A and PE analysts a while ago to understand what your daily work looks like, specifically processes like due diligence and model building. The work you all do is incredibly demanding, and I have a lot of respect for it. I've talked to some amazingly smart and talented people in the field, which has left a profound impression on me.
Getting down to it: from the conversations I’ve had so far, tracking down financial inconsistencies and catching errors in massive models seems painful and warrants a lot of manual investigation. Disclaimer, I may be wrong on this, and I’d love to be corrected. But from what I’ve heard, there might be headroom for dedicating a bit of time into this, that could result in potentially a helpful tool.
So, I’ve been working on a side project called Altaire, which at the core is a custom machine learning model I built, that sits silently in the background, connects to your VDR, and maps every copied-over number in your workbook back to its original source document. Because it builds this hidden map, it can act almost like a Grammar Checker. I'm trying to make it proactively use this interesting data to then hunt for anomalies like fat-finger mistakes, transposed numbers, formula mistakes, or mismatched dates in invoices. To smooth it out I'm strapping Google Gemini securely on top as a secondary feature so you describe an issue and have it investigate across source documents to find culprits of inconsistencies. I've attached a screenshot so you can see what the tool currently looks like, I've put it against Apples 2016 10-K in EDGAR Excel format against a SharePoint filled with a full history of their 10-K filings in EDGAR PDFs. I'd like to emphasize that it's super-super early stage and riddled with problems, as you can see the matching system is performing significantly sub-par in this example. There are other tests I've done where it performs fortunately better but I'd like to stick with this clean SEC-based example here, as it's better to convey and reproduce. And showing the case where your tool performs the worst hopefully signals transparency and humbleness in a pursuit to improve.
Here’s where I’m stuck. I trained the initial document-to-cell matching engine on synthetic data to navigate the obvious NDA limitations in the sector, but my synthetic data is way too "clean." It completely lacks the messy, real-world nuances of actual financial models and seller-side VDR documents. I need to test this properly, but I obviously can’t (and shouldn't) get my hands on live deal documents.
Because of this, I’m looking for directions. If anyone can point me toward publicly available resources that include realistic financial data and models, that would help immensely in pushing this from a fun side project to a genuinely useful tool.
For example, I've seen friends participate in university case competitions (like HEC, CBS, or the NIBC), which I assume provide public sample data and financial case materials. Additionally, publicly available course materials, textbook exercises with accompanying Excel models, or freely shared interview modeling tests would be perfect.
To be clear, and I know this is common sense, please do not share anything confidential, proprietary, or protected by NDA. To protect everyone's confidentiality and avoid any accidental sharing of live data, I am keeping this strictly to public replies in this thread. I am only looking for materials that are already public or explicitly made available by the creators. I have massive respect for the confidentiality standards in this industry and have no intention of crossing those lines.
Finally, I know your time is valuable, and I don't want to just show up asking for favors without giving back. Since I can't offer any finance expertise, I’d like to offer what I do know. I know you often deal with highly repetitive data formatting tasks, and writing a quick script to automate those things is usually straightforward for me. If you are able to drop a helpful public link in the comments, please feel free to describe a repetitive Excel task you hate doing. I would be more than happy to write a custom PowerQuery, Python script, or VBA macro for you right here in the thread. It’s simply my way of trading skills and saying thank you for pointing me in the right direction.
Thank you for reading, and for any pointers you can give a self-taught engineer trying to learn about your world.
TL;DR:
I’m building a Machine Learning tool that connects to your VDR and silently traces every number in your workbook back to its source document to surface errors (fat-finger mistakes, transposed numbers, formula issues) or help you find them. It’s quite early stage and I've been searching for realistic, publicly available practice files (e.g., case competition materials, textbook Excel models, interview modeling tests) to test against and improve it. Only public stuff please, nothing under NDA. In return, I’d be happy to help out (read: last paragraph).
Hope you have a sunny start into the weekend!
Best,
Robin Röper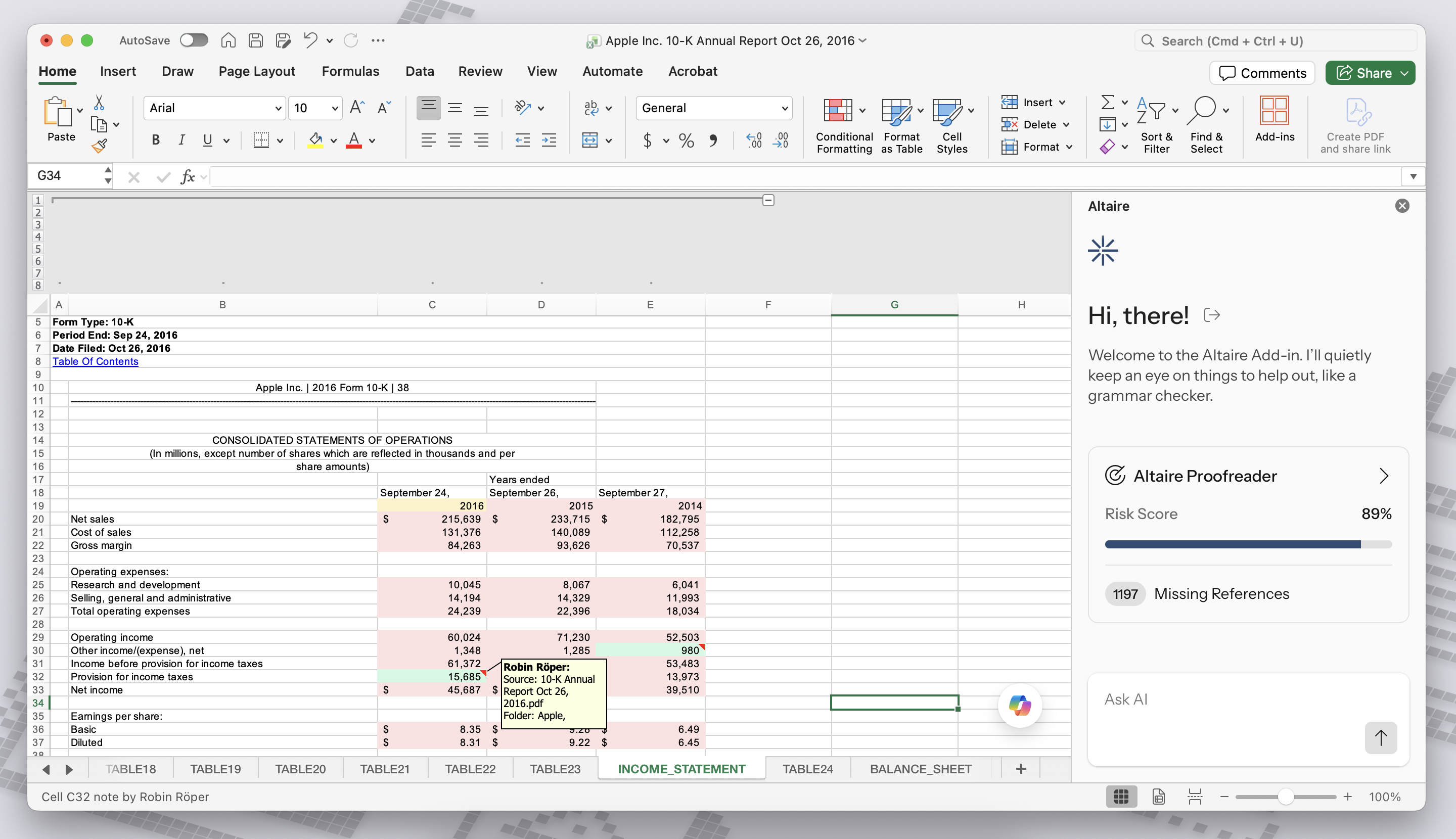




Based on the most helpful WSO content, here are some suggestions to help you find publicly available resources for realistic financial data and models to test your project:
Case Competitions: Many universities and organizations host case competitions that provide publicly available financial models and case materials. Examples include:
WSO Financial Modeling Templates: Wall Street Oasis offers a variety of financial modeling templates, including:
Public Filings and Reports: Use publicly available financial statements and filings from platforms like EDGAR (for U.S. companies) or other regulatory bodies. These documents often include detailed financial data that can be converted into Excel models.
Interview Modeling Tests: WSO has a section dedicated to interview questions and answers, including investment banking and private equity interview modeling tests. These tests often simulate real-world scenarios and can be a valuable resource.
Finance Textbooks and Courses: Many finance textbooks include exercises with accompanying Excel models. Additionally, online courses (e.g., Coursera, Udemy) sometimes provide downloadable practice files.
WSO Community Forums: Engage with the WSO forums, where users often share insights and resources. You might find threads discussing publicly available financial models or case studies.
If you’re looking for specific links or further guidance, feel free to explore the WSO templates and resources mentioned above. Good luck with your project, and kudos for your innovative approach to tackling M&A due diligence challenges!
Sources: https://www.wallstreetoasis.com/forum/investment-banking/any-suggestions-for-ib-case-study-resources-online?customgpt=1, Where to find recent deals, Public Finance IB to PE?, Case Competition on Resume
Very cool. I have no data I could provide you, but this is a very interesting and respectable pursuit
Bump + following
Et aliquam occaecati eum est. Fugit voluptatem et blanditiis sit ea ratione. Inventore delectus eius ipsa eveniet dolores commodi. Aspernatur quae ratione molestiae at voluptatem.
See All Comments - 100% Free
WSO depends on everyone being able to pitch in when they know something. Unlock with your email and get bonus: 6 financial modeling lessons free ($199 value)
or Unlock with your social account...