I may be a dumb southerner who limped through advanced calculus like a wounded animal, but I spent a fair amount of time in college studying math and applied statistics. (I think it is amazing you can graduate from many institutions with a degree in finance, having memorized a bunch of formulas with absolutely no clue how the underlying math works--or doesn't).
Seth Klarman (prospective monkey tip: you should know who he & Baupost are) wrote in his annual letter about his fears that Trump will create volatility and uncertainty. (NYT Article)
This got me thinking back to my days in data mining, regression modeling, and other topics. As well as Klarman's earlier observation:
When the markets reverse, everything investors thought they knew will be turned upside down and inside out. ‘Buy the dips’ will be replaced with ‘what was I thinking?’ Just when investors become convinced that it can’t get any worse, it will. They will be painfully reminded of why it’s always a good time to be risk-averse, and that the pain of investment loss is considerably more unpleasant than the pleasure from any gain.... ...Correlations of otherwise uncorrelated investments will temporarily be extremely high.
Considering that correlations are the bedrock of pretty much everything in predictive analytics, and the fact that 70%(?) of market volume is algorithmic trading based on predictive analytics, wouldn't this create a problem? It seems to me that there is a potential that the old models stop working, at least temporarily.... Who will provide the liquidity and volume? Will HFT firms be forced to take the hit or be allowed to just turn the machines off? Remember (or read about) when that happened in 2010? I heard that as a risk management proposal recently: here. --- Pure stupidity IMHO
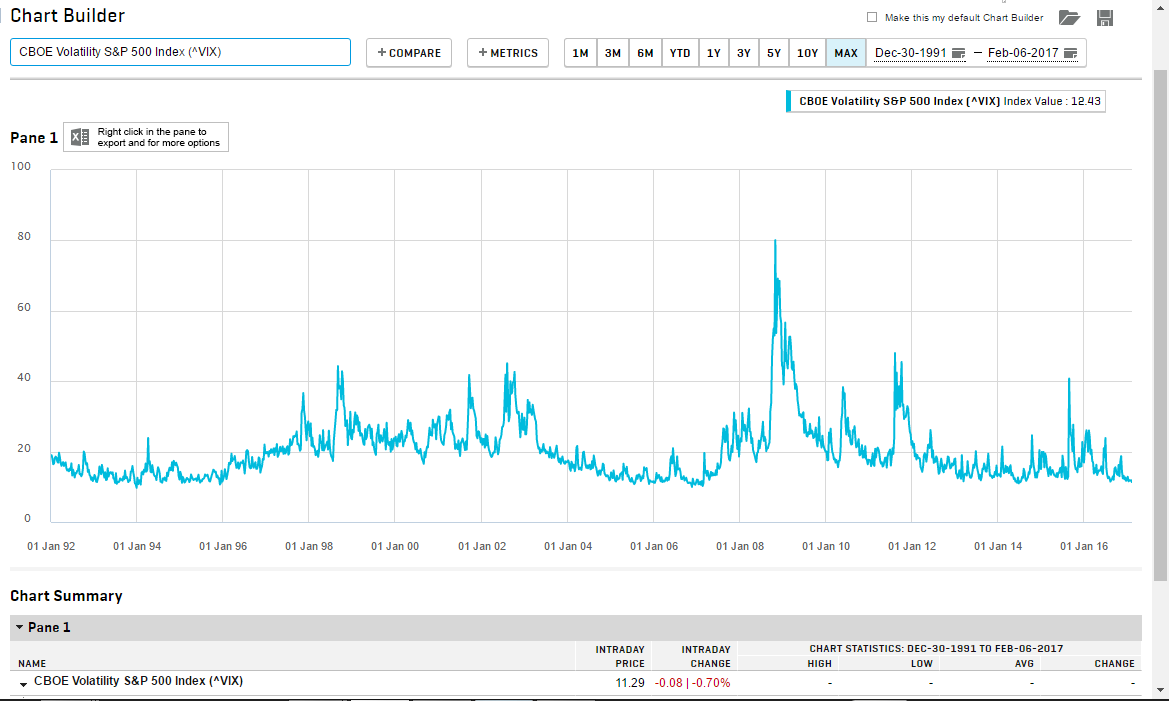
Furthermore, for strategies that rely on models built on more historical data, if they dynamics of the market change for whatever reason, geopolitical, financial or otherwise (thus changing the correlations).. wouldn't this render them useless? To my understanding, they have all been built and tuned in the last ~decade, where markets have steadily climbed, volatility (correct me if I am wrong) has been pretty low, and everything has been skewed by QE 'forever'. As every value disciple knows, that can all change, and when it does.. it usually changes pretty quickly. Didn't LTCM blow up for similar reasons? And aren't most of the quants too young (or any of us for that matter) to remember Scholes ran a hedge fund that blew up anyway?
I was hoping some of you young Haim Bodeks could climb out of the dark pools and throw some color on this.
On a side note I was a double major, one of which was in econ, where my econometrics professors thought the analytics department were a bunch of quacks and we were always cautioned by the analytics department about relying on models, "ALL ARE WRONG, SOME ARE USEFUL, SOMETIMES."
PS if you have the full text of the Klarman letter (and I know some of you are going to go find it now). Fucking post it. Don't be a jackass.
Throwback Thursday - this post originally went up a year ago and is pretty relevant to what's going on these days in the market.
| Attachment | Size |
|---|---|
| vix.png 56.85 KB | 56.85 KB |




{kind=link}
{kind=link}
-Quantitative models adapt to new market conditions. Just like a self driving car can drive in the open freeway, it can transition to driving in the busy city streets.
-LTCM blew up because of assumptions about the risk free rate of their beloved black scholes equation. Turns out that rate wasn't entirely risk free (See russian collapse).
-Certainly some hft shops will not do well if there is an increase in volatility or a downturn. The best 20% (Jane Street, DE Shaw, etc.) will be fine.
I don't work at a hft shop but we look at data stretching back to the 70s. Our models are not just tuned for the past 10 years. I can't imagine most the hft firms have only tuned their models based off of the last 10-15 years because that creates all kinds of survivorship bias and other types of biases.
In short, quant shops fill be fine.
My concern is they are using trading data that wasn't available 10.. 15.. years ago. The self driving car analogy is great. But didn't Boston dynamics teach robots to walk on new surfaces by letting them take a tumble? A tumble here could be costly. If you 'slow down the self driving car' here to avoid an accident... wouldn't that mean trading less and thus less liquidity? Would that further compound the problem?
To my understanding, predictive models do not do well with unpredictable events. Though they can learn from them afterwards. Sounds like a lot of unpredictable things might be on the horizon.
Thanks for the response. I did some stuff that worked ok.. but I am by no means an expert. Just never my focus.
You can "let the model tumble" without actually trading the market. This is why when trying to tune the parameters of a model, quants will run all kinds of simulations to maximize the model's ability to generalize to new data and situations. Don't take the data at face value. Inject different levels of noise into your data and see how well it performs. Always randomly select data to train your model and then test thousands or millions of times. When training a model, always use many different initial conditions.
I would definitely push back that predictive models do not do well with unpredictable events. It really depends on how good your model is. If your model isn't taking into account enough complexity then you'll have issues. Now that quant shops are moving away from traditional quantitative financial models and towards machine learning (my area of focus), quantitative models will be much better at predicting 'unpredictable' events.
The issue with quantitative models of the past is that there were far too many hard coded assumptions. Returns are normally distributed. The risk free rate is risk free. Variable X should always be positively correlated with variable Y. It is these hard coded assumptions that humans have put into the models that is what makes stuff go poorly. The less assumptions you have to make, the better. With so much computing power, these hard coded assumptions are becoming less necessary to make. Machine learning systems are now able to learn what those assumptions are and discard them if they are no longer true. Funds that have incorporated machine learning into their trading processes well (which is the majority of the top funds at this point) are going to continue to thrive. Those that continue to rely on outdated assumptions will not.
Fascinating. This brings me to another concern.. If everyone is using machine learning isn't there a lot of overlap? Isn't everyone using similar training techniques on roughly the same data? Are there any sort of foreseeable risks there?
There is so much that falls under the umbrella of "machine learning". It's really kind of a buzz word. The majority of the algorithms that people call "machine learning" have existed for decades or more. It's just that the computing power only recently caught up with the math. Machine learning systems take inputs from regressions and input the results from regressions into decision trees, which get output into neural networks, etc. The permutations and combinations of approaches that you can take to model systems as complex as financial markets are endless so I am not personally worried that there is a lack of diversification of models out there but that is definitely a really interesting thing to think about.
There was a cool paper I read recently (will link when I find it) about how long it takes for new research papers on quantitative finance to become irrelevant due to market efficiency. The paper found that after about 3 months, the trading advantage you got from using the strategy identified by the researchers is gone.
One of my senior colleagues (who's a physicist) made a very interesting point. When you discover a new law or phenomenon in physics, that's it. That's just how the world works and it doesn't really change. There are no such laws in predicting financial markets. Something that was true 3 months ago is often no longer true today.
SB'd
If you could accurately simulate the next "crash" or "bubble", wouldn't that mean you would know how it would happen? Seems like a logical hole.
I was going to comment on LTCM, but glad you covered it. +sb
Excessive leverage and the market staying irrational longer then you can stay solvent is a lesson all should learn.
I am most certainly not a quant guy and will never be one (not that I aspire to ever become one), but after reading the OP and proceeding discussion I have to say this is just plain good.
Have enjoyed reading this and gleaning a little more insight into a vastly complex world. Wish more WSO threads would follow this pattern. SBs to both of you.
I don't have a finance background so this site has actually been pretty helpful for me. Glad I can help give back every once in a whle
Totally understand, I would see my analytics professors handle stock market data and would just end up shaking my head. Even though some of them (unlike my finance professors) were quite brilliant.
OP reminded me of the basics of Nassim Taleb's mantra. In his Fooled By Randomness he talks a lot about "blowing up", his love of being risk-averse, why models built on the past are irrelevant in his opinion.
Thanks to OP and DeepLearning for the expansive convo. SBs to both.
Taleb is such an interesting guy. Love his work.
I read a book in college about cycles in politics that loosely used some data science. Wasn't very robust but still interesting how cycles are considered valid and you can use math to study them in a political science context but in the context of finance and markets trends don't exist as far as many academics were concerned. Particularly by the faculty at my school, who called it a pseudoscience as my buddy sat next to me racking up the dough in the futures markets.
Just a slight note (that is important..). LTCM didn't collapse because of bad bets, it collapsed because it couldn't make the margin calls. Successful FI Arb funds have a massive amount of their AUM in cash/cash-like instruments to make margin calls.
If LTCM could've made the margin calls, the trades would have been profitable.
Do you have a source for this? I watched a documentary on it once that had the LTCM guys in it.. if my memory serves me correctly they recounted being down huge.
Sure thing - here is a quick video of Bob Treue (one of the greatest minds in FI Arb investing) discussing LTCM.
http://www.opalesque.tv/youtube/Bob_Treue/index.php
Watch starting at 13:00
He's correct: LTCM's strategy and positions were good, but they made fatal errors when it came to liquidity. If I remember correctly, Warren Buffet was actually attempting to step in and buy those positions, since, as I said, they were actually good positions based on a good strategy. Ultimately, however, the deal fell apart at the 11th hour due to contractual issues.
LTCM wasn't in pure arbs. They had exposures that were anything but arbs. And they were leveraged very high. I'm sure LTCM had the aum in cash like instruments. Problem is they were running out of cash to post as positions got bad.
Guys it's me, Jon Meriweather. The truth is, we blew up because an intern added an extra zero in a trade order and e*trade filled it. What're you gonna do. That's life
Do you want to be financially independent? PM me for an exclusive invite to a premier residential real estate investing seminar at Foxwoods Resort Casino next weekend
Ain't nobody wanna climb out of their dark pools. They are way too cozy.
This is a pretty interesting topic, hopefully I’m not too late.
Systematic strategies exploit some combination of market inefficiencies, behavioral biases, and various risk premia (liquidity provision, bearing asymmetric risks, etc.). Very broadly, these kinds of opportunities are often larger in difficult markets, and the quant approach tends to perform quite well in such conditions. So for the most part, quants are not so worried about general volatility and uncertainty - those are often our best times. If this Trump bull market reverses and goes bad, I know quite a few people in this neck of the woods will be very pleased.
Binary one-off events like the election or Brexit are generally outside the wheelhouse of systematic investors and traders because they are, by definition, not systematic. I would have very little confidence in my ex-ante ability to predict a Trump win last year. For that reason, we largely ignore such things, modulo perhaps some minor adjustments to make extra sure we don’t have huge unintended exposure to some upcoming event.
Quants can get away with this moreso than others because their holdings at any point in time are typically un-concentrated, and hedged with respect to undesired sources of risk. Most quant strategies are all about taking as many independent bets as possible, whether that’s via cross-sectional diversification or through speed and rapid turnover. So is it possible you wound up long GBP last June and got burned? Sure, but A) it could have easily been the opposite, since you weren’t even thinking about the vote outcome when you put on your trades (so assuming the event is independent of your signals, you're flat on it in expectation), and B) it probably can’t have hurt you too badly since the individual bet was likely only a small part of your portfolio’s risk.
At the same time, it’s totally fair to be worried about freak tail events on a large scale. Moreso than LTCM’s comically levered carry-like trades being a bad idea, I think of something like the 2007 quant meltdown. Other people with strategies (and thus, positions) just like yours needing to liquidate en masse for some unrelated reason? Potential nightmare situation. I think risk management has come a long way in minimizing the potential for serious blowups, but by definition these are the things you don’t see coming.
In the event of a huge, instantaneous crash (rarer than one would perhaps expect; the financial crisis was actually much “slower” than you’d think, and was definitely telegraphed to some), even rock-solid strategies could run into problems. A strong model can’t help you when you’re getting margin called and forced to let go of positions that your signals are screaming at you to hold, or even increase. Of course, these risks aren't unique to quant strategies, though. You mentioned HFTs “turning off” and letting a market crash rather than catching the falling knife and providing liquidity, which is also a very valid concern and could exacerbate the possibility for such a crash.
@DeepLearning (nice name, by the way), I don’t really agree that current machine learning methods can easily generalize to totally unseen events in these situations. It’s always been a huge problem when train and test data come from different distributions. Topically to the previous conversation, think about why current self-driving cars aren’t just an end-to-end reinforcement learning problem: with a stochastic policy and a large state space, you can easily find yourself somewhere you’ve never been before, and good live behavior in those situations is far from guaranteed. Like in the driving problem, mistakes in trading can be very costly, so it’s often difficult to have faith in a true black box even if overall accuracy is high, because it’s impossible to know how your model will react to truly new circumstances (which, admittedly, are extremely rare). Machine learning has been around in finance for a long time, but doing trading end-to-end in the style of modern deep learning solutions seems very far off. We're getting better very quickly, though.
I think these considerations are why it’s still hugely important to truly understand your strategies. It is not enough to have good performance, backtested nor realized. You need to understand: why does my strategy work? Who am I taking money from? What kinds of risks am I bearing (these may not be obvious)? When can I blow up? The smartest people I know are much more concerned with these questions than the magnitude of a predictive t-stat.
Skimmed the top. DM me tomorrow afternoon and remind me if I forget to reply.
Well, I thought I was going to be writing a more in depth response but it's actually more simple. You're thinking a lot about individual strategies but I'm thinking in aggregate. It all comes down to liquidity. Here's a scenario: If 70% of the market volume is based on algorithms, which temporarily stop working, and we lose a significant portion of that liquidity because they slow them down or turn them off.. this could lead to a major problem... further messing up the predictive models... decreasing the liquidity... and so fourth
DeepLearning makes excellent points, but I'm still not convinced the next crisis won't by sparked by, compounded by, maybe even created by algorithmic strategies acting in aggregate. And while he presents a defensible argument for an algorithmic strategy that takes place at a slow speed.. we have had no input from anyone with HFT experience. If they're using neural networks and random forests, the potential exists for a correlation inspired calamity.
“Algorithms” constitutes a pretty heterogenous group of market participants, so let’s just talk about electronic market makers when we say “HFT”.
It seems you’re worried about two things. (1) Trading algorithms may cause a sell-off as a result of a bug or unpredictable model behavior in response to new conditions, and (2) in the event of a crash, HFTs may pull out of the market and exacerbate liquidity crises. Both are reasonable points.
(1) is fair to be concerned with, but I think is not very likely. The actual computations being made at any point in time are generally not that complicated because they need to be fast. Might there be neural networks involved? Maybe (although even a forward-pass evaluation of a trained network of decent size might already be too slow), but these are no “AI” systems making a complex decision based on the state of the world. They’re pretty rule-based and simple to interpret, and don’t have too much capacity to surprise you. Market making is very mechanical. Anyone that’s ever worked with software knows that bugs always happen, but these systems are extraordinarily robust.
Risk triggers are also tight. Nobody’s forgotten about Knight or the flash crash, so HFTs have a pretty low threshold for pulling quotes when markets seem “weird". Because sizable losses are rare, you can set a very tight loss limit before you just get flat and stop trading. Exchanges also have controls to halt electronic trading. So for the most part, (1) can just be rolled into (2); if anything crazy happened, caused by an algorithm or not, HFTs as a whole would pull out of the market before they went haywire.
As such, (2) is absolutely true. It is a fact that the liquidity HFTs provide would probably vanish in market crashes, when the market “needs” it the most. But I’ll defend HFT a little here.
HFTs probably aren’t creating the sell-off. They avoid holding large inventory at any point in time, so their liquidation probably is not meaningfully affecting the selling. They know there's no liquidity, so putting out more sell quotes once flat is too scary. If anything, in a panicked state, not only is the premium/spread sellers are willing to pay very large, but the affected securities can be bought at great discount to fair value. So buying and providing liquidity at some point actually becomes very attractive (how long was the flash crash?), whether for HFTs or someone slightly slower with different goals. In fact, quantitative strategies work to keep prices efficient, so large corrections like ’87 are less likely to begin with.
Some rhetorical questions then. What else do people want? For HFTs to jump in front of a train and buy to slow a crashing market? Does anyone really think that’s what a “designated market maker” would’ve done in the good old days? An exchange can’t force anyone to lose millions of dollars for the sake of a stable market. Is this situation any worse than in a world with no algorithms? I don’t have a good answer for what would happen, and part of me does agree with you, but it doesn't seem totally fair to blame HFT for creating this risk.
Algos are not pure liquidity. They aren't the portfolio manager actually buying something and relieving the pressure on the market.
I predict a big rally tomorrow once the long only managers get a shot to really buy a dip. Not sure how low we go tonight as its margin call time.
That's a good point about reinforcement learning in self-driving cars. I suppose that's why online learning is all the rage these days anyway. Anything that's not a toy problem will have a massive state space and no training data set will be enough.
https://en.wikipedia.org/wiki/Online_machine_learning
I'm sure that these self-driving cars are utilizing online learning at least in part. I think quants are moving towards this too. Online learners generally recover and learn new behavior pretty quickly, which I think will help minimize probability of disaster.
In short, I think the nature of the non-convexity imposed by machine learning objective functions will lead to a greater diversity of trading strategies, which will help minimize the type of mass-crash that you are talking about. I believe that the primary source of systematic risk created by quantitative strategies is naive assumptions to make models more mathematically and computationally simple. It is these model assumptions, in my view, that lead to correlation inspired calamity. I won't argue that it is impossible for this type of situation to be created by machine learning algorithms, but the diversity of strategies that can be uncovered from machine learners is unarguably greater than from traditional quantitative finance.
At the risk of getting crazy off-topic (what site are we on again?) and overburdening this self-driving car analogy. Current self-driving cars to my knowledge are far from “engineering-free”. They still use a lot of old, tried-and-true robotics techniques (SLAM, simple filters), and although deep learning may play a part in the system (CNNs in the vision module, say), they still rely quite a bit on simplifying assumptions and imposed structure. Machine learning simply isn’t there yet to do it all from scratch.
Similarly in finance, I think. “Machine learning” isn’t a trading strategy, just a tool, so wherever it’s being used must be in the context of a strategy designed by humans. So it seems unavoidable that you still need to incorporate a priori information. I get what you’re saying about optimization rarely reaching the same minima, and maybe no two people are using the exact same algorithm or model. But we’re all thinking about the same problems, looking at the same datasets, approximating the same functions. Implementation details matter, but probably not as much as the fundamental priors we frequently share.
Fair point about online learning for nonstationary data, although I don’t really buy that this translates to fast adaptation to unseen inputs (one-shot or few-shot learning is a pretty wide-open problem). I've also liked your other examples about eg. effectively augmenting your sample with collaborative filtering. Still, there’s so much complexity you'd want to model, so little data, and so much noise. HFT brings additional challenges; you have plenty of data, but static backtests and simulations are less relevant due to a lack of decision-dependent market impact.
Sorry if this comes off as negative, I’m actually very into ML and follow the research pretty closely. There’s just too much hype recently, and I’m worried about being disappointed. ML has always been useful, but I don’t think the hyper-ambitious claims about AI in finance are substantiated. This isn't directed at you - as an example, the “AI hedge fund” linked in @George Kush’s original post doesn’t disclose their performance (if it were good, why wouldn’t you?), but they still feel the need to garner publicity through media interviews and build hype. Tech has seen success throwing LSTMs at some of their problems, and seem to think this approach will work for trading and that the quant hedge fund industry is ripe for "disruption". It's all very arrogant, to me.
Great discussion! I know this is WAY off topic but I am just really shocked at Klarman's statement (unless the article misquote) that "tax cuts could drive government deficits considerably higher."
Coolidge, JFK, Reagan, and Bush 43 all lowered taxes and it led to large increases in tax revenue. I think the Bush era tax cuts led to a 44% increase in tax revenues. Don't know how this could "fuel income inequality and huge federal deficits" according to Klarman when 43 had the dotcom & subprime bubbles.
Sorry for the tangent. I am just really shocked he said that.
Let's not hijack the thread for another WSO political MS throwin bonanza but I think he meant in the context of the Trump administration, who, is betting that they will be able to outrun the increase in expanding federal spending (particularly on infrastructure?) by increasing tax revenue with a more optimistic economy and cutting wasteful spending at every level of government... which I'm sure is rampant
So we'll see how that plays out, we're long/short so I'm just along/ashort for the ride
DeepLearning EightyTwo you guys should do an AMA. I invest with some of the top quant shops on behalf of clients, and I find the space fascinating (mostly because while I understand why it works, I can't begin to comprehend the details of the math).
great thread
I would be willing to do that. Granted I actually havent been in quantitative finance for very long. Maybe next week.
This might not be the right venue. The details you'd want probably couldn't be discussed, and once we have to get rid of those questions there are only so many ways to answer "how do I break in".
Is it possible that computer algorithms could be used to manipulate the market and induce other algorithms to learn the wrong signals and cause some type of faulty learning? Even induce failure?
They already do that on a millisecond basis with phantom orders
But can you imagine a type of economic warfare waged in this way by another country or entity? Surely beyond me in how something so complex could be arranged and thought out but interesting to ponder none-the-less. Even with an engineer/programmer close by monitoring it.
Called it
https://www.bloomberg.com/news/articles/2018-02-05/machines-had-their-f…
DeepLearning AndyLouis
Haha yeah looks like the trend following/momentum HFT algos got carried away today. It mostly corrected itself quickly. The big drop to 1600 was probably caused by the algos but I don't think the market drop as a whole was some super odd event. There were human factors involved there. Curious to see what happens tomorrow. SPX futures are trading lower after hours pretty significantly which is pretty crazy.
Reading this thread, I think DeepLearning and some of the others were thinking you menat that Quants would be wiped out because of the Trump presidency and volatility causing signals to send the algos bizerk, losing bags of money to the funds running them.
But I read it as you were thinking that the "Quant-mageddon" would be the similarity to a flash crash or some sort of selloff largely led by algos, perpetuated by volatility from the Trump presidency. For the record, I too predicted that Trump would be the cause of the next correction and I think his policies could lead to us seeing some sort of economic retrenchment during his presidency, not necessarily 2008 all over, though. I think that's far too difficult to predict, at least for me, anyway.
But great read here.
I think the takeaway from today (and the last flash crash) is that many of the "algorithms" that are out there in the market, particularly in the HFT space are not that complex or nuanced. They follow a set of rules that have empirically worked well but may not have a solid fundamental basis. When you have algorithms that are designed using such rules, shit like this will happen.
Algorithms that are using fundamental data (from financial statements, credit card txs, satellites, web intelligence, mobile traffic, etc.) rather than just momentum indicators will not exhibit this kind of behavior.
I want to second what DeepLearning has been saying in his post here as well as previously in this thread. Any model, especially "black box" models that are prevalent in HFT are only as strong as the data they are trained and cross-validated on.
The issue that George Kush is concerned about is essentially that of "overfitting". This is a term used in model evaluation which, in laymans terms, means "The risk that the model makes an inaccurate prediction because it is using dissimilar conditions from the past to guide its understanding of the present".
I think DeepLearning is saying that in the context of modeling market behavior, when you introduce "fundamental" variables to your model, you reduce the potential for overfitting, because you are grounding the model in what I would call "primary source" data - i.e. the economic data that companies and governments produce which are proximate to the actual enterprise being evaluated. Things like the unemployment rate, GDP growth, net margin, etc. These data reduce overfitting because they are minimally dependent on anything other than the actual health (or lack thereof) of the underlying economic process.
By contrast, many models take into account "technical" factors that are abstract concepts, and are measurements of the market's behavior itself. While these technical data have been shown to be useful as heuristics (i.e. "buy this security when this oscillator falls below a certain level"), they are unique in that they are relative measurements that depend upon a high-dimensional process, in this case the operation of the underlying market.
The issue with models that are light on fundamental analysis is that they will become "overfit" to the prevailing norms of the times in which they are trained. For example, a model trained and cross-validated on market data collected in the past decade will make assumptions about volatility that aren't representative of history, because if we look back even one more decade, these prevailing conditions (really, those created by aggressive global QE) no longer hold.
So in short, the predictions rendered by trading models are reflections of the prevailing trends in the data upon which they are trained. With a diverse selection of data that is done intentionally to avoid overfitting, these models can be "robust" to changes in the prevailing norms.
good one, ill put this put up again on Thur
I have a pdf of some personal photos from a family trip I took back in January that I think everyone would like to see.
https://dropfile.to/39A7nwz
Distinctio voluptatum iure quae magni praesentium. Voluptatem accusamus ducimus rerum quia non iure rerum velit. Exercitationem sed corporis voluptatum autem. Id autem ipsa ex itaque consectetur laudantium. Dignissimos sit incidunt inventore aut odit in. Natus sunt tempora ullam vitae omnis voluptatibus sunt.
Harum non et vel omnis. Quia qui alias laborum quisquam. Fugit laudantium aperiam quibusdam nesciunt et dolore eaque velit. Quasi reprehenderit ipsa mollitia assumenda. Qui voluptas deleniti qui qui error enim sed ut. Eligendi consequatur rem omnis non.
Ut molestias sunt nihil dolorum ipsam fugiat hic. Nihil laboriosam ducimus labore. Quibusdam necessitatibus dolore earum odit et atque possimus. Omnis consequatur explicabo minima facilis sequi ipsam. Ut voluptates enim magni sed facere ipsum. Est praesentium amet eos et et. Est sapiente voluptas ab nemo.
Molestiae et et inventore. Culpa eius et incidunt odit tempore molestias. Nulla enim voluptatem officia eaque non. Quo dicta aperiam assumenda voluptatem culpa ducimus. Numquam in nobis voluptas nihil. Ea eum sit aut ipsam earum atque aliquam.
See All Comments - 100% Free
WSO depends on everyone being able to pitch in when they know something. Unlock with your email and get bonus: 6 financial modeling lessons free ($199 value)
or Unlock with your social account...
Explicabo eius enim nulla assumenda quia et cumque. Quis ipsam voluptatem nihil esse dolor et. Consequatur aut nemo alias. Laborum impedit atque ut hic.
Repudiandae culpa impedit libero iure. Illum quia vero occaecati porro deserunt cumque perspiciatis. Quo architecto enim est.
Laborum corrupti quod culpa omnis. Esse ipsum dolorem omnis hic. Quo dolor quidem qui ut nihil et.